Capitolo 6 Appendice: breve introduzione ad R
Cosa è R?
R è un software cugino di S-PLUS, con il quale condivide la gran parte delle procedure ed una perfetta compatibilità. Rispetto al cugino più famoso, è completamente freeware (sotto la licenza GNU General Public Licence della Free Software Foundation) ed è nato proprio per mettere a disposizione degli utenti uno strumento gratuito, potente, che permette di lavorare in modo estremamente professionale, senza usare software di frodo. Inoltre, si tratta di un programma Open Source, cioè ognuno può avere accesso al suo codice interno ed, eventualmente, proporne modifiche o ampliarne le funzionalità programmando apposite librerie aggiuntive.
A fronte di questi vantaggi, bisogna tuttavia considerare il fatto che R, almeno all’inizio, presenta alcune difficoltà legate al fatto che manca una vera e propria interfaccia grafica (Graphical User Interface: GUI) e, di conseguenza, ogni operazione deve essere eseguita digitando il codice necessario. Parte di queste difficoltà possono essere alleviate utilizzando R dall’interno di RStudio, un’interfaccia che garantisce una più facile digitazione del codice.
Installazione di R
Per iniziare, segui questi semplici passaggi:
- Installa R da: https://cran.r-project.org. Segui il link a CRAN (in alto a destra), seleziona uno dei mirror disponibili (puoi semplicemente selezionare il primo link in alto), seleziona il tuo sistema operativo (SO) e scarica la versione base. Installala utilizzando tutte le opzioni predefinite.
- Installa RStudio da: https://posit.co/download/rstudio-desktop/. Seleziona la versione desktop di RStudio, edizione open source e scaricala. Installala utilizzando tutte le opzioni predefinite.
- Avvia RStudio.
6.1 Prima di iniziare
Ci sono alcune nozioni che è bene conoscere prima di mettersi al lavoro con R. Riassumiamole:
- Case sensitivity. Per evitare noiosi errori che possono essere molto comuni per chi è abituato a lavorare in ambiente WINDOWS, è bene precisare subito che R, come tutti i linguaggi di derivazione UNIX, è case sensitive, cioè distingue tra lettere maiuscole e lettere minuscole.
- Spazi. Gli spazi possono essere aggiunti ovunque nel codice per renderlo più leggibile. Tuttavia, non si possono aggiungere spazi all’interno dei nomi delle funzioni, dei nomi degli oggetti e degli operatori composti da più di un carattere.
- Pannelli. In RStudio, ci sono quattro pannelli e noi ne utilizzeremo prevalentemente due, denominati, rispettivamente SOURCE e CONSOLE. Il codice si scrive nel pannello SOURCE, che è un semplice editor di testi, salvabili con l’estensione ‘.R’. Il codice composto nel pannello SOURCE DEVE essere inviato alla console, dove viene eseguito, utilizzando i tasti ‘ctrl-r’ (Windows) oppure ‘ctrl-invio’ (Windows) o ‘cmd-invio’ (Mac). Se il codice non è inviato alla console non viene eseguito: è come scrivere un messaggio in Whattsapp, senza inviarlo al destinatario!
- Operatori. In informatica e programmazione, un operatore è un simbolo che specifica quale operazione applicare ad uno o più operandi, per generare un risultato. Si distinguono in (1) aritmetici (+, -, * e /); (2) di assegnazione (<- oppure =); (3) logici (TRUE, FALSE, & e |); (4) Condizionali (if); (5) di relazione (<, <=, ==, >= e >)
6.2 Oggetti e assegnazioni
In R, si lavora creando ‘oggetti’ ed assegnando loro un nome, che identifica la porzione di memoria in cui questo oggetto viene collocato. Nel principio, questo è molto simile a quello che facciamo in un foglio elettronico, dove assegniamo un oggetto (lo memorizziamo) in una determinata cella. Ad esempio, il comando:
assegna al valore numerico 3 il nome y. Invece il comando:
assegna al testo “Biondo” il nome x.
I dati che possiamo includere in un oggetto sono di diverso tipo:
- numerici a doppia precisione;
- ‘integer’, cioè numeri senza parte decimale
- carattere (con virgolette, ad es. “Germinato”, “Non germinato”)
- valori logici (TRUE o FALSE, abbreviati in T o F).
6.3 Tipi di oggetti
Gli oggetti che possiamo creare sono di diverso tipo, principalmente:
- costanti,
- vettori,
- matrici,
- dataframes.
6.3.1 Costanti e vettori
Le costanti sono, ad esempio, quelle indicate in precedenza, ma, solitamente, in R si creano oggetti più organizzati, come i ‘vettori’, cioè degli elenchi di dati dello stesso tipo. Ad esempio, il codice segente crea un vettore di nome x, contenente i numeri 1, 2 e 3. Bisogna precisare che il ‘vettore’, in R, non ha alcun legame con la fisica o l’algebra, ed è semplicemente una collezione di elementi affini.
Oltre che numerici, i vettori possono contenere testi alfanumerici. Ad esempio, nel codice sottostante abbiamo creato un vettore contenente nomi di persona.
Un oggetto leggermente diverso è il fattore sperimentale (‘factor’), che contiene caratteri alfanumerici (come nel caso precedente), ma rappresenta una variabile qualitativa di classificazione in categorie.
6.3.2 Matrici
Oltre ai vettori, in R possiamo definire le matrici. Ad esempio il comando:
crea una matrice z a 2 righe e 4 colonne, contenente i numeri da 1 a 8. La matrice viene riempita per riga.
6.3.3 Dataframe
Oltre a vettori e matrici, in R esiste un altro importante oggetto, cioè il dataframe, costituito da una tabella di dati con una o più colonne di variabili e una o più righe di dati. A differenza della matrice, il dataframe può essere utilizzato per memorizzare variabili di diverso tipo (numeri e caratteri). Un dataframe può essere creato unendo più vettori, come nell’esempio seguente; fare attenzione a non confondere il nome assegnato alla colonna, con il nome del vettore il cui contenuto viene immesso nella colonna stessa (nel codice sottostante, “Parc” = parcelle significa che la prima colonna della tabella si chiama “Parc” e contiene i dati del vettore ‘parcelle’).
6.4 Lavorare con gli oggetti
6.4.2 Indicizzazione
Vettori, matrici e dataframe sono oggetti organizzati caratterizzati da una o due dimensioni. Gli elementi che sono in essi contenuti possono essere identificati per mezzo di ‘indici’, un po’ come avviene nella battaglia navale. Gli indici sono inclusi tra parentesi quadre. Ad esempio, il secondo elemento del vettore ‘x’ creato in precedenza può essere richiamato in questo modo:
Nel caso delle matrici e dei dataframes, che sono oggetti bidimensionali, gli indici sono due, uno per le righe e uno per le colonne, separati da virgole:
Per questi oggetti bidimensionali, è possibile anche accedere agli elementi di un’intera riga o di un’intera colonna, lasciando vuoto l’indice relativo ad una delle due dimensioni. Ad esempio:
oppure:
6.4.3 Estrazione di slots
A volte gli oggetti contengono altri oggetti ai quali è possibile accedere con l’estrattore \(*. Per esempio, si può accedere alle singole colonne di un dataframe, oltre che con l'indicizzazione, anche utilizzando l'estrattore *\) seguito dal nome della colonna, ad esempio:
6.5 Espressioni, funzioni e argomenti
Gli oggetti numerici possono essere creati e manipolati anche con opportune operazioni algebriche (espressioni), utilizzando gli operatori indicati in precedenza. Ad esempio:
Le operazioni più complesse ed usuali sono implementate in apposite funzioni, che hanno un nome ed uno o più argomenti. Ad esempio, la funzione:
restituisce il valore assoluto e richiede un solo argomento, cioè il numero di cui calcolare il valore assoluto. Al contrario, la funzione:
Calcola il logaritmo in base 2 di 100 e richiede due argomenti, cioè il numero di cui calcolare il logaritmo e la base del logaritmo. A volte, gli argomenti hanno valori di default, per cui, se digitiamo:
otteniamo il logaritmo naturale di 5, in quanto il secondo argomento (la base) ha, per default, il valore \(e\) (operatore di Nepero).
Quando sono necessari due o più argomenti essi debbono essere messi nell’ordine esatto in cui R se li aspetta (in questo caso prima il numero, poi la base), oppure possono essere specificati per nome. Ad esempio, i due comandi:
restituiscono lo stesso risultato, al contrario dei due comandi seguenti:
perchè il primo restituisce il logaritmo di 100 in base 2, mentre il secondo restituisce il logaritmo di 2 in base 100. Per conoscere gli argomenti di una funzione ed il loro ordine, si può digitare il nome della funzione preceduto dal punto interrogativo:
?logCome menzionato in precedenza, a volte le funzioni restituiscono diversi risultati, che vengono messi in appositi ‘slots’. Ad esempio, se vogliamo calcolare autovettori ed autovalori di una matrice, utilizziamo la funzione ‘eigen()’. Questa funzione restituisce una lista che, al suo interno, contiene i due oggetti, denominati, rispettivamente, ‘values’ (autovalori) e ‘vectors’ (autovettori). Per recuperare l’uno o l’altro dei due oggetti (autovettori o autovalori) si usa l’estrattore ‘$’, come abbiamo visto prima per le colonne dei dataframes:
6.6 Funzioni di uso comune
Nella pratica operativa, ci troviamo spesso nelle condizioni di creare una serie di numeri progressivi, utilizzando il comando seq(n, m, by=step), che genera una sequenza da \(n\) a \(m\) con passo pari a \(step\). Il codice sottostante crea una serie da 1 a 12.
Altre volte, abbiamo la necessità di creare vettori, ripetendo più volte alcune categorie. Ad esempio, potremmo avere quattro osservazioni che appartengono alla varietà BAIO, quattro osservazioni che appartengono alla varietà DUILIO e quattro osservazioni che appartengono alla varietà PLINIO. Per creare velocemente questo vettore, possiamo utilizzare la funzione rep(), in questo modo:
tesi <- factor(c("BAIO", "DUILIO", "PLINIO"))
tesi
## [1] BAIO DUILIO PLINIO
## Levels: BAIO DUILIO PLINIO
rep(tesi, each=4)
## [1] BAIO BAIO BAIO BAIO DUILIO DUILIO DUILIO
## [8] DUILIO PLINIO PLINIO PLINIO PLINIO
## Levels: BAIO DUILIO PLINIONotare l’uso della funzione factor() per creare un vettore di dati qualitativi (fattore sperimentale). Notare anche che il codice sottostante restituisce lo stesso risultato, ma ordinato in modo diverso, in quanto viene ripetuto l’intero vettore, non i singoli elementi che lo costituiscono:
rep(tesi, times = 4)
## [1] BAIO DUILIO PLINIO BAIO DUILIO PLINIO BAIO
## [8] DUILIO PLINIO BAIO DUILIO PLINIO
## Levels: BAIO DUILIO PLINIOUn’altra funzione molto usata è ‘str()’ che permette di avere informazioni sulla struttura di un oggetto creato in R:
str(tabella)
## 'data.frame': 6 obs. of 3 variables:
## $ Parc : num 1 2 3 4 5 6
## $ Tesi : Factor w/ 3 levels "A","B","C": 1 1 2 2 3 3
## $ Produzioni: num 12 15 16 13 11 19R ci informa che l’oggetto ‘tabella’ è in realtà un dataframe composto da tre colonne, di cui la prima e la terza sono numeriche, mentre la seconda è una variabile qualitativa (fattore).
Altre informazioni riassuntive su un oggetto possono essere ottenute con la funzione ‘summary()’, che fornisce un output diverso a seconda dell’oggetto che le viene passato come argomento:
summary(nomi)
## Length Class Mode
## 4 character character
summary(classe)
## Donna Uomo
## 3 2
summary(tabella)
## Parc Tesi Produzioni
## Min. :1.00 A:2 Min. :11.00
## 1st Qu.:2.25 B:2 1st Qu.:12.25
## Median :3.50 C:2 Median :14.00
## Mean :3.50 Mean :14.33
## 3rd Qu.:4.75 3rd Qu.:15.75
## Max. :6.00 Max. :19.00Tra le funzioni di uso comune, citiamo quelle che si impiegano per fare alcune semplici operazioni su un dataframe, come l’ordinamento o la selezione di records. Ad esempio, è possibile estrarre da un dataframe un subset di dati utilizzando la funzione ‘subset()’:
tabella2 <- subset(tabella, Tesi == "A" | Tesi == "C")
tabella2
## Parc Tesi Produzioni
## 1 1 A 12
## 2 2 A 15
## 5 5 C 11
## 6 6 C 19Notare il carattere “|” che esprime la condizione logica OR. La condizione logica AND si esprime con il carattere “&”. L’esempio seguente isola i record in cui le varietà sono A o C e, contemporaneamente, la produzione è minore di 19.
tabella3 <- subset(tabella, Tesi == "A" | Tesi == "C" &
Produzioni < 19)
tabella3
## Parc Tesi Produzioni
## 1 1 A 12
## 2 2 A 15
## 5 5 C 11Un vettore (numerico o carattere) può essere ordinato con la funzione ‘sort()’:
y <- c(12, 15, 11, 17, 12, 8, 7, 15)
sort(y, decreasing = FALSE)
## [1] 7 8 11 12 12 15 15 17
z <- c("A", "C", "D", "B", "F", "L", "M", "E")
sort(z, decreasing = TRUE)
## [1] "M" "L" "F" "E" "D" "C" "B" "A"Un dataframe può essere invece ordinato con la funzione order(), facendo attenzione al segno meno utilizzabile per l’ordinamento decrescente.
dataset[order(dataset$z, dataset$y), ]
dataset[order(dataset$z, -dataset$y), ]6.7 Creazione di funzioni personalizzate
Anche se R contiene tantissime funzioni, a volte ci troviamo nella necessità di creare una funzione personale, se questa non fosse già disponibile. Immaginiamo, ad esempio, di voler scrivere una funzione che, dato il valore della produzione rilevata in una parcella di orzo di 20 $ m^2 $ (in kg) e la sua umidità percentuale, calcoli automaticamente il valore della produzione secca in kg/ha. La funzione che dobbiamo implementare è:
\[ PS = PU \cdot \frac{100 - U}{100} \cdot \frac{10000}{20}\]
dove PS è la produzione secca in kg/ha e PU è la produzione in kg per 20 $ m^2 $ con l’umidità percentuale U. Il codice è:
Notare l’uso delle parentesi graffe. Una volta creata ed inviata alla console, la funzione può essere utilizzata come ogni altre funzione di R:
6.8 Uso di librerie aggiuntive
Le funzionalità di R possono essere anche estese installando librerie aggiuntive. Il comando è:
install.packages("NomeLibreria")Un libreria si installa ‘una tantum’, ma va caricata ogni volta che la si vuole usare:
library("NomeLibreria")6.9 Workspace
Gli oggetti creati durante una sessione di lavoro vengono memorizzati nel cosiddetto workspace (ambiente di lavoro). Per il salvataggio del workspace nella directory corrente si usa il menu (File/Save Workspace) oppure il comando:
save.image('nomefile.RData')Il contenuto del workspace viene visualizzato con:
ls()Il workspace viene richiamato da menu (File/Open Workspace) oppure con il comando:
load('nomefile.RData')Per un lavoro efficiente in R è bene tenere il workspace molto pulito, eliminando gli oggetti non necessari. La completa eliminazione degli oggetti nel workspace si esegue con:
rm(list=ls())Uno o più oggetti specifici possono essere eliminati con:
rm(oggetto1, oggetto2, .....)Gli oggetti possono anche essere richiamati in base alla loro posizione; ad esempio il comando:
rm(list=ls()[3:4])elimina il terzo e il quarto oggetto dal workspace.
Un comando particolarmente utile è il seguente:
rm(list=ls()[ls()!="oggetto1"])che permette di eliminare dal workspace ogni oggetto meno “oggetto1”. Si possono utilizzare anche clausole logiche più articolate come la seguente:
rm(list=ls()[ls()!="oggetto1" & ls()!="oggetto2"])che elimina tutto meno “oggetto1” e “oggetto2”.
6.10 Importare dati esterni
Oltre che immessi da tastiera, i dati possono essere importati in R da files esterni, ad esempio in formato EXCEL. Per essere importata, una tabella deve essere in formato ‘ordinato’ (tidy data), vale a dire:
- la prima riga dovrebbe contenere i nomi delle colonne
- ci dovrebbe essere una riga per ogni soggetto
- ci dovrebbe essere una colonna per ogni attributo dei soggetti
Detto ciò, avremo bisogno di una libreria addizionale, che dovremo installare (‘una tantum’) e poi caricare in memoria, utilizzando il codice sottostante:
A questo punto, in R, possiamo digitare il seguente comando, che permette di selezionare un file, tramite una ‘form’ di selezione e, da questo, importare il foglio di lavoro con il nome ‘Foglio1’.
dati <- read_xlsx(file.choose(), sheet = "Foglio1")
datiPer importare un file di testo (ad esempio in formato comma delineated, cioè .csv) si utilizza il seguente comando:
dataset <- read.csv("NomeFile.csv", sep = ";", dec = ",")dove gli argomenti ‘sep’ e ‘dec’ permettono di specificare, rispettivamente, il separatore di elenco e il separatore decimale. E’ possibile anche esportare un dataframe in un file di testo, con il codice seguente:
write.table(nomeDataframe, file = "residui.csv",
row.names=FALSE,
sep=";", dec = ",")6.11 Cenni sulle funzionalità grafiche in R
R è un linguaggio abbastanza potente e permette di creare grafici interessanti. Ovviamente un trattazione esauriente esula dagli scopi di questo testo, anche se è opportuno dare alcune indicazioni che potrebbero essere utili in seguito.
La funzione più utilizzata per produrre grafici è:
plot(x, y, type, xlab, ylab, col)dove x ed y sono i vettori con le coordinate dei punti da disegnare, ‘type’ rappresenta il tipo di grafico (‘’p’’ produce un grafico a punti, ‘’l’’ un grafico a linee, ‘’b’’ disegna punti uniti da linee, ‘’h’’ disegna istogrammi), ‘xlab’ e ‘ylab’ le etichette degli assi, ‘col’ è il colore dei punti/linee.
Per una descrizione più dettagliata si consiglia di consultare la documentazione on line. A titolo di esempio, i comandi mostrati qui sotto producono l’output in Figura 6.1.
x <- c(1, 2, 3, 4)
y <- c(10, 11, 13, 17)
plot(x, y, type = "p", col="red", xlab="Ascissa", ylab="Ordinata")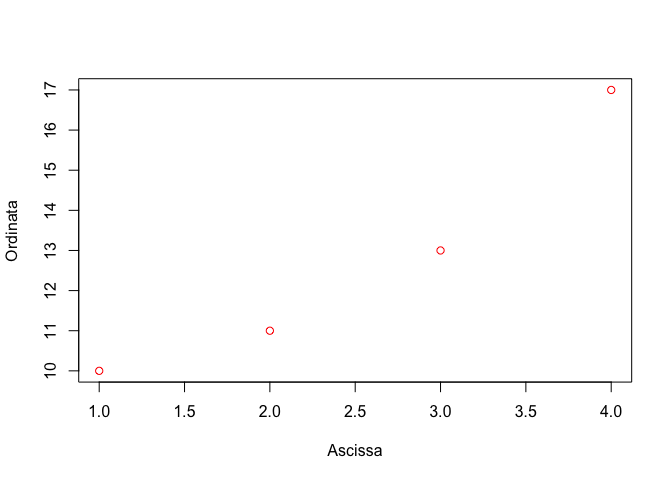
Figura 6.1: Esempio di un semplice grafico a dispersione
Per sovrapporre una seconda serie di dati alla prima possiamo utilizzare la funzione ‘plot()’, come sopra e, successivamente la funzione ‘points()’ per aggiungere la nuova serie. Il risultato è quello mostrato in Figura 6.2.
y2 <- c(17,13,11,10)
plot(x, y, type = "p", col="red", xlab="Ascissa", ylab="Ordinata")
points(x, y2, col="blue")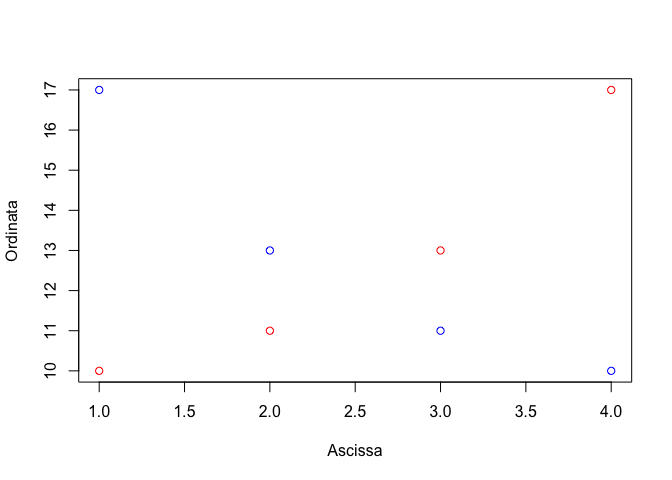
Figura 6.2: Esempio di grafico con due serie di dati
Se avessimo voluto sovrapporre un grafico a linee avremmo potuto utilizzare la funzione ‘lines()’ al posto della funzione ‘points()’, ottenendo l’output in Figura 6.3.
plot(x, y, "p", col="red", xlab="Ascissa", ylab="Ordinata")
points(x, y2, col="blue")
lines(x, y2, col="blue")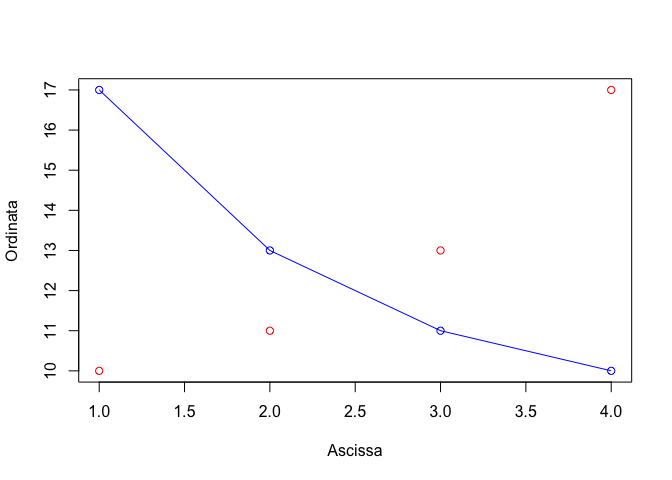
Figura 6.3: Esempio di grafico con due serie di dati, con linee e punti
Per disegnare una curva si può utilizzare la funzione ‘curve()’ ottenendo, ad esempio, l’output in Figura 6.4.
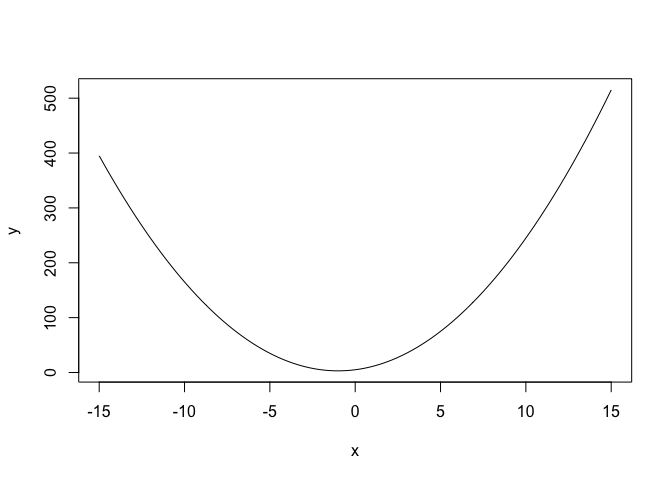
Figura 6.4: Esempio di una parabola
Un grafico a barre può essere ottenuto con il codice indicato più sotto, che produce il grafico in Figura 6.5 e che è di facile interpretazione.
Produzioni <- c(10, 12, 13, 15, 17)
Genotipo <- c("A", "B", "C", "D", "E")
barplot(Produzioni, names.arg = Genotipo,
ylab = "Produzioni (t/ha)",
main = "Produzioni di diversi genotipi di mais")
Figura 6.5: Esempio di grafico a barre
L’ultima cosa che desideriamo menzionare è la possibilità di disegnare grafici a torta, utilizzando il comando:
pie(vettoreNumeri, vettoreEtichette, vettoreColori)Ad esempio il comando sottostante, produce l’output in Figura 6.6.

Figura 6.6: Esempio di grafico a torta
6.12 Altre letture
- Maindonald J. Using R for Data Analysis and Graphics - Introduction, Examples and Commentary. (PDF, data sets and scripts are available at JM’s homepage.
- Oscar Torres Reina, 2013. Introductio to RStudio (v. 1.3). This homepage